Artificial Intelligence (AI) has revolutionized the way we analyze data and derive insights, and at the heart of this revolution lies machine learning techniques such as supervised and unsupervised learning. In this article, we will dive deep into the world of unsupervised learning, explore its key differences compared to supervised learning, and uncover strategies to master this powerful tool for data analysis.
Understanding the Foundations: Exploring Supervised vs. Unsupervised Learning and Their Key Differences
What is Supervised Learning?
Supervised learning is a type of machine learning where the model is trained on a labeled dataset. Each input data point is associated with a corresponding output label, which guides the model in learning the relationship between inputs and outputs. This method is highly effective for tasks where historical data can be used to predict future outcomes.
Key Characteristics:
- Labeled Data: Requires a dataset with predefined labels.
- Goal: Predict or classify new data based on learned patterns.
- Applications: Spam detection, image classification, and sales forecasting.
Example:
Consider a dataset of email messages labeled as either “spam” or “not spam.” A supervised learning algorithm can use this data to predict whether a new email belongs to one of these categories.
What is Unsupervised Learning?
In contrast, unsupervised learning deals with unlabeled datasets. The goal is not to predict specific outcomes but to identify hidden patterns, groupings, or structures within the data. This makes unsupervised learning especially useful for exploratory data analysis and understanding complex datasets.
Key Characteristics:
- Unlabeled Data: Works with datasets that lack predefined labels.
- Goal: Discover inherent structures or relationships in the data.
- Applications: Customer segmentation, anomaly detection, and recommendation systems.
Example:
Imagine a dataset containing customer purchasing behavior without any labels. An unsupervised learning algorithm can cluster customers into distinct groups based on their buying habits, enabling businesses to tailor marketing strategies.
Comparing Supervised and Unsupervised Learning
Understanding the differences between these two approaches is essential for choosing the right method for your specific needs:
| Feature | Supervised Learning | Unsupervised Learning |
|---|---|---|
| Dataset Type | Labeled | Unlabeled |
| Goal | Predict outcomes | Identify patterns |
| Techniques | Regression, classification | Clustering, dimensionality reduction |
| Example Algorithms | Linear regression, decision trees | K-means, PCA |
| Applications | Fraud detection, stock price prediction | Market segmentation, outlier detection |
By mastering the foundational differences between supervised and unsupervised learning, you can make informed decisions about which approach best suits your data analysis tasks. The next step involves delving deeper into unsupervised learning techniques, which we will cover in subsequent sections of this guide.
Real-World Applications: How Supervised and Unsupervised Learning Drive Innovation in AI Solutions
The rise of Artificial Intelligence (AI) has transformed industries across the globe, from healthcare to retail, thanks to its ability to analyze vast amounts of data and generate actionable insights. Central to this revolution are supervised and unsupervised learning techniques. This article explores how these approaches are applied in real-world scenarios and how they drive innovation.
Supervised Learning in Action
Supervised learning has a clear objective: predict outcomes based on labeled datasets. Its structured approach makes it a go-to method for solving many practical problems. Let’s explore some of its impactful applications:
1. Fraud Detection
- Challenge: Detect fraudulent activities in financial transactions.
- Solution: Supervised learning models analyze historical transaction data, identifying patterns associated with fraudulent behavior. By training on labeled datasets (e.g., “fraudulent” vs. “legitimate” transactions), these models can flag suspicious activities in real-time.
2. Medical Diagnosis
- Challenge: Accurately diagnose diseases based on patient data.
- Solution: AI models trained on labeled medical datasets (e.g., symptoms, test results, and diagnoses) help healthcare professionals detect diseases early, recommend treatments, and improve patient outcomes.
3. Customer Churn Prediction
- Challenge: Identify customers at risk of leaving a service.
- Solution: Supervised learning models analyze customer behavior data, such as purchase history and engagement metrics, to predict churn and allow companies to take proactive retention measures.
Unsupervised Learning in Action
Download the free ebook

Unsupervised learning, on the other hand, excels in discovering hidden patterns and structures in unlabeled datasets. This approach is particularly useful for exploratory analysis and data organization. Below are some of its key applications:
1. Customer Segmentation
- Challenge: Group customers into distinct segments for targeted marketing.
- Solution: Clustering algorithms, such as K-means, group customers based on purchasing behavior, demographics, and preferences. Businesses can then design personalized marketing campaigns.
2. Anomaly Detection
- Challenge: Identify unusual patterns in data, such as network intrusions or defective products.
- Solution: Algorithms like Isolation Forests or Principal Component Analysis (PCA) can pinpoint anomalies, helping organizations prevent costly issues.
3. Recommendation Systems
- Challenge: Suggest products or services that align with user preferences.
- Solution: Collaborative filtering and clustering methods identify patterns in user interactions, enabling personalized recommendations for e-commerce, streaming platforms, and more.
Step-by-Step Approach: Training AI Models Using Supervised Learning
Mastering AI involves a clear understanding of how to build and implement machine learning models effectively. Below is a structured approach for both supervised and unsupervised methods:
Training AI Models Using Supervised Learning
- Define the Problem: Clearly identify the prediction or classification task.
- Collect and Label Data: Gather high-quality, labeled datasets relevant to the task.
- Preprocess Data: Clean and normalize the data to eliminate noise and inconsistencies.
- Choose an Algorithm: Select a suitable algorithm, such as linear regression, decision trees, or neural networks.
- Train the Model: Split the data into training and validation sets, and use the training set to fit the model.
- Evaluate Performance: Assess the model using metrics like accuracy, precision, recall, or F1-score.
- Optimize: Tune hyperparameters or experiment with different models to improve performance.
Unlocking Data Insights with Unsupervised Learning
- Understand the Data: Analyze the dataset to identify key features and characteristics.
- Preprocess the Data: Normalize and scale data to improve clustering or dimensionality reduction outcomes.
- Select an Algorithm: Choose a technique such as K-means for clustering or PCA for dimensionality reduction.
- Apply the Model: Run the unsupervised algorithm on the data to uncover patterns or groupings.
- Visualize Results: Use tools like scatter plots or heatmaps to interpret the model’s outputs.
- Iterate and Refine: Experiment with different algorithms or parameters to refine insights.
By leveraging supervised and unsupervised learning techniques effectively, organizations can unlock the full potential of their data. From predicting future trends to uncovering hidden patterns, these approaches continue to fuel innovation and drive transformative AI solutions in today’s data-driven world.
Advanced Techniques: Optimizing Performance and Achieving Accuracy in Both Supervised and Unsupervised AI Models
The ability to optimize and achieve high performance in machine learning models is critical for their success in solving real-world problems. Whether working with supervised or unsupervised learning models, there are several advanced techniques to refine accuracy, improve efficiency, and ensure robust results. This article explores these techniques and provides actionable insights to help data scientists and engineers excel in AI model optimization.
Optimizing Supervised Learning Models
1. Feature Engineering
Careful selection and transformation of features significantly impact model performance. Key strategies include:
- Feature Selection: Use techniques such as Recursive Feature Elimination (RFE) or mutual information to identify the most relevant features.
- Feature Creation: Combine or transform existing features to generate new ones that better capture patterns in the data.
- Feature Scaling: Apply normalization or standardization to ensure that features contribute equally to model learning.
2. Model Selection
Choosing the right algorithm for a specific task is crucial. Factors to consider include:
- Complexity of the Problem: Linear models may suffice for simple tasks, while neural networks are better for complex data.
- Dataset Size: Algorithms like Random Forests or Gradient Boosting perform well with smaller datasets, whereas deep learning models excel with larger datasets.
3. Hyperparameter Tuning
Fine-tuning hyperparameters is essential for maximizing model performance. Approaches include:
- Grid Search: Test all combinations of hyperparameters to find the optimal configuration.
- Random Search: Randomly sample hyperparameter combinations to save computational time.
- Bayesian Optimization: Use probabilistic models to iteratively refine hyperparameters.
4. Regularization Techniques
Prevent overfitting by penalizing overly complex models:
- L1 Regularization (Lasso): Encourages sparsity by reducing less significant coefficients to zero.
- L2 Regularization (Ridge): Penalizes large coefficients to ensure smoother models.
- Dropout: Used in neural networks to randomly deactivate neurons during training.
Optimizing Unsupervised Learning Models
1. Data Preprocessing
Unsupervised learning algorithms are sensitive to data quality. Essential preprocessing steps include:
- Outlier Removal: Detect and eliminate outliers to prevent skewed clustering or dimensionality reduction results.
- Dimensionality Reduction: Use techniques like Principal Component Analysis (PCA) or t-SNE to reduce data complexity while preserving essential information.
- Data Normalization: Standardize data to ensure fair treatment of all features.
2. Algorithm Selection
Different algorithms suit different types of unsupervised tasks. For example:
- Clustering: Use K-means for spherical clusters, DBSCAN for irregular shapes, or hierarchical clustering for nested data structures.
- Anomaly Detection: Apply Isolation Forest or One-Class SVM to identify outliers.
- Dimensionality Reduction: Choose PCA for linear relationships or UMAP for preserving non-linear structures.
3. Model Evaluation
Unlike supervised learning, evaluating unsupervised models often lacks ground truth labels. Common evaluation methods include:
- Silhouette Score: Measures how well each data point fits within its cluster.
- Elbow Method: Helps determine the optimal number of clusters by analyzing the variance explained.
- Reconstruction Error: Used in autoencoders to evaluate how well the reduced representation captures the original data.
Achieving Accuracy in Both Types of Models
1. Ensemble Techniques
Combine multiple models to improve robustness and accuracy:
- Bagging: Train models on different subsets of the data and aggregate their predictions (e.g., Random Forests).
- Boosting: Sequentially train models to correct previous errors (e.g., Gradient Boosting, AdaBoost).
2. Cross-Validation
Divide the dataset into training and validation sets multiple times to ensure the model performs consistently across unseen data.
- Use K-Fold Cross-Validation to divide data into K subsets and validate each fold iteratively.
3. Monitoring and Iterative Refinement
Model performance can degrade over time as data evolves. Implement:
- Drift Detection: Monitor data distributions to identify changes that may affect model accuracy.
- Active Learning: Continuously incorporate new labeled data into supervised models to maintain relevance.
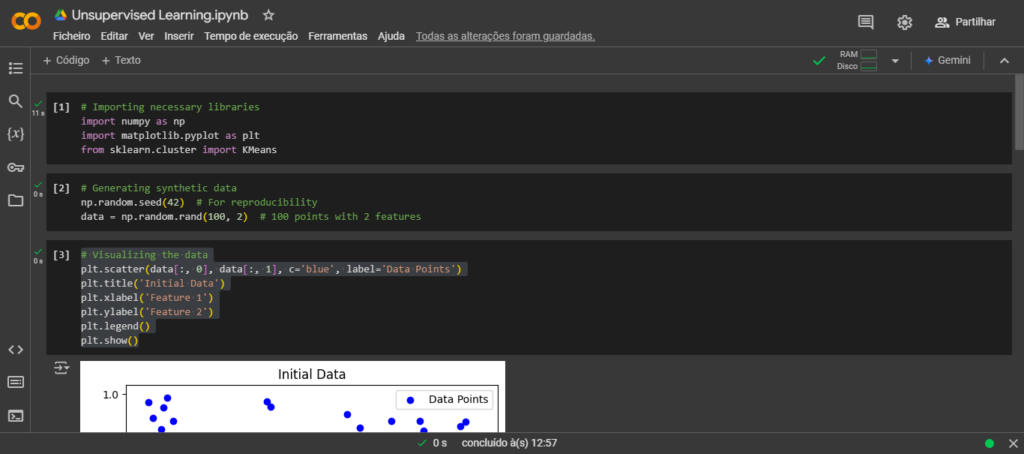
Here is a simplified Python code for unsupervised learning using k-means clustering. This example clusters data points into groups based on their features. Below the code, I’ll explain it in detail.
Code for Google Colab:
# Importing necessary libraries
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
# Generating synthetic data
np.random.seed(42) # For reproducibility
data = np.random.rand(100, 2) # 100 points with 2 features
# Visualizing the data
plt.scatter(data[:, 0], data[:, 1], c='blue', label='Data Points')
plt.title('Initial Data')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.legend()
plt.show()
# Applying k-means clustering
kmeans = KMeans(n_clusters=3, random_state=42) # Specify 3 clusters
kmeans.fit(data) # Train the model
# Getting the results
centroids = kmeans.cluster_centers_ # Centroid locations
labels = kmeans.labels_ # Cluster labels for each data point
# Visualizing the clusters
for i in range(3): # Loop through each cluster
cluster_points = data[labels == i]
plt.scatter(cluster_points[:, 0], cluster_points[:, 1], label=f'Cluster {i+1}')
plt.scatter(centroids[:, 0], centroids[:, 1], c='red', marker='x', s=100, label='Centroids')
plt.title('Clustered Data')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.legend()
plt.show()
Explanation in American English:
- Importing Libraries:
numpyfor creating and manipulating arrays.matplotlib.pyplotfor data visualization.sklearn.cluster.KMeansfor the k-means clustering algorithm.
- Generating Synthetic Data:
- We create 100 random data points with 2 features using
np.random.rand. These points are uniformly distributed between 0 and 1.
- We create 100 random data points with 2 features using
- Visualizing the Data:
- The data points are plotted on a 2D graph to understand their initial distribution.
- Applying K-Means Clustering:
- We use the k-means algorithm from
sklearnto divide the data into 3 clusters. The parametern_clusters=3specifies the number of clusters, andrandom_state=42ensures consistent results.
- We use the k-means algorithm from
- Training the Model:
- The
fitmethod is used to find the best cluster centroids for the given data points.
- The
- Results:
kmeans.cluster_centers_gives the coordinates of the cluster centroids.kmeans.labels_assigns each data point to a cluster (label 0, 1, or 2).
- Visualizing Clusters:
- We loop through the clusters and plot the points belonging to each cluster in a different color.
- The cluster centroids are marked with red crosses (
x) for clarity.
Output:
- Initial Data: A scatter plot showing random points.
- Clustered Data: A scatter plot with points grouped into three clusters, and centroids marked.
This example demonstrates the basic concept of unsupervised learning with clustering, which is often used for grouping data without predefined labels.
Conclusion
Optimizing supervised and unsupervised AI models requires a combination of advanced techniques tailored to the dataset, task, and desired outcomes. By mastering feature engineering, hyperparameter tuning, regularization, and algorithm selection, practitioners can significantly enhance their models’ performance. Furthermore, maintaining iterative refinement processes ensures that AI solutions remain effective in ever-changing environments. As AI continues to evolve, these strategies will be instrumental in driving innovation and delivering impactful results.

Download the free ebook